Computing power, also known as computing capability, is the core driving force of the information age. The size of computing power directly affects the speed and efficiency of data processing. And computing power can only become true productivity if it is rooted in the industry.

The key to transforming computing power into productivity lies in the deep integration with industrial demand. For example, the traditional manufacturing industry has low production efficiency and high energy consumption, which has given rise to the demand for edge computing power and intelligent computing power. By deploying edge computing nodes in the production line, real-time processing of massive data collected by sensors, and then using AI computing power to optimize production processes, intelligent manufacturing is realized. The core driving force for the upgrading and iteration of computing power technology comes from these practical industry pain points.
The evolution from “cloud centralization” to “end-to-end cloud distribution”

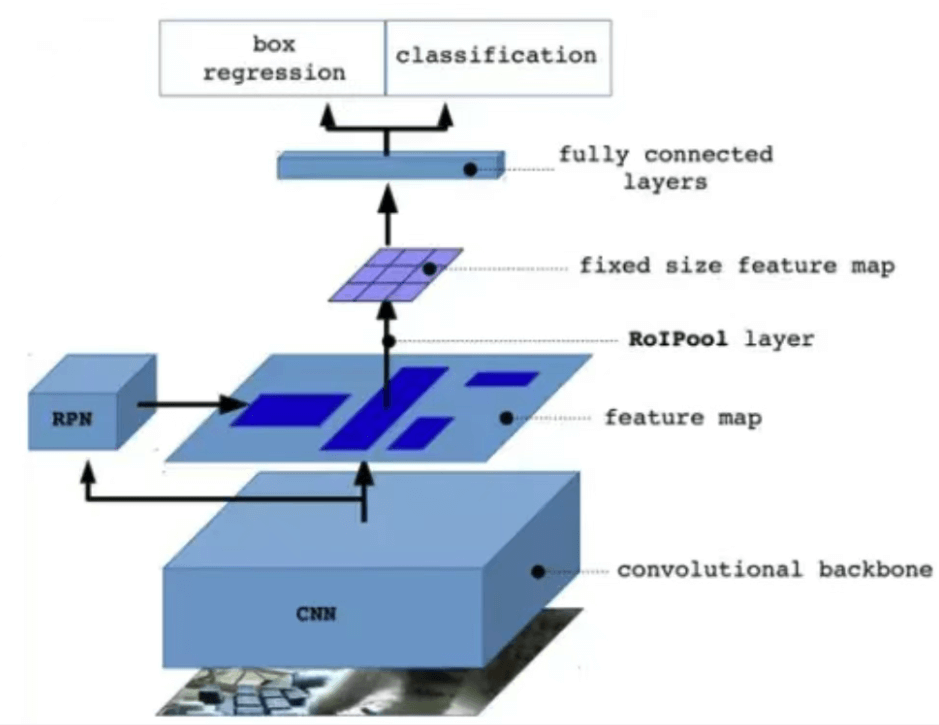
Based on the pain point of the industry – the deep development of AI visual inspection, it has upgraded from a simple “model training tool” to a “full process R&D tool” – covering the entire lifecycle of data collection, annotation cleaning, model training, deployment reasoning, monitoring and operation. However, traditional platforms heavily rely on cloud centric architecture, which gradually exposes two core contradictions in practical implementation:
Explosive data growth and cloud transmission bottleneck: In industrial scenarios, the number of defective data increases. If all of it is uploaded to the cloud, it will occupy more than 70% of industrial bandwidth, leading to network congestion.
Real time decision-making requirements and cloud latency shortcomings: Industrial quality inspection requires millisecond level response (such as defect detection on high-speed production lines), while cloud processing (including network transmission) typically has an average latency of over 100ms, which cannot meet real-time requirements.
The core of these contradictions is essentially the mismatch between “centralized computing architecture” and “distributed business requirements”. The emergence of edge computing has extended computing power from the cloud to the “edge” of the physical world, providing a new paradigm for solving the above contradictions.
KEYETECH Redefine the ‘computing power boundary’ of AI
KEYETECH-AI edge computing is not simply “distributed computing”, but sinks data processing, storage, AI reasoning capabilities to physical devices or “edge nodes” close to data sources, forming an “end edge cloud” collaborative architecture. Its core values are reflected in four aspects:
High computing power:
The AI edge computing unit of KEYETECH can process 400-500 image data per second with a single computing power of 32TOPS.
Low latency:
Local data processing avoids long-distance network transmission, and end-to-end latency can be reduced from 100ms+in the cloud to within 10ms (depending on the distance between edge nodes and devices).
Bandwidth optimization:
After filtering, cleaning, and extracting features from the raw data, edge nodes can only upload key information, reducing data transmission by more than 90%.
Higher stability
The edge side often faces the problem of network instability. KEYETECH-AI edge computing unit has certain autonomy, supports offline AI reasoning, and ensures that critical tasks can still be run when the network is disconnected.
The “third-order synergy” of data, models, and computing power
KEYETECH-AI edge computing unit developed by KEYETECH-AI itself forms an end edge cloud collaborative architecture, which is not a simple division of labor, but a deep integration of three dimensions.
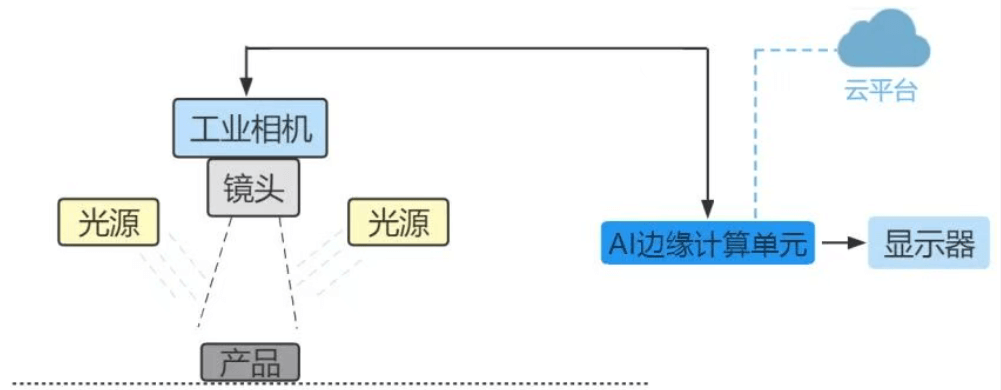
Data Collaboration
The edge is responsible for data collection, preprocessing, and feature extraction, while the cloud is responsible for data storage, annotation, and big data analysis, forming a closed-loop data flow of “edge filtering cloud precipitation”.
Model collaboration
Cloud based training of universal large models, edge deployment of lightweight models, and implementation of “cloud optimization edge inference” model lifecycle management through model compression, parameter updates, federated learning, and other technologies.
Collaborative computing power
Dynamically allocate edge and cloud computing power based on task real-time, complexity, and resource requirements (such as edge priority for real-time tasks and cloud processing for non real time tasks), achieving the optimal configuration of global computing power resources.
Compared with traditional centralized computing, the core advantage of edge computing lies in “low latency (millisecond response)”, “bandwidth optimization (more than 70% reduction of invalid data upload)”, “localization decision (still able to run independently when disconnected)”, which just matches the core demands of predictive maintenance on real-time and reliability.
The path of KEYETECH’s self-developed computing power is not only a technological breakthrough, but also a reconstruction of the essence of industrial productivity – using specialized computing power to solve the universal dilemma, defining reliability standards with stability, and achieving green intelligent manufacturing with low power consumption